Automatic Data Ingestion in Finance
There’s no doubt that automation is changing, for the better, business performances in finance. Automating data extraction and ingestion adds value to finance departments and institutions.
A recent survey by Dun & Bradstreet of finance operations in the US and the UK showed that improved speed of processes was the leading motivator for ushering in automation, followed by cost savings.
The study concluded that when propelled by analytics, automation could cut down operational costs, boost efficiency, and help open more avenues of growth for finance teams by scaling and pulling in data from multiple sources at once.
Not only that, the report said enterprises that were driven by data and insights were 39 percent more likely to report year-over-year revenue growth of 15 percent or more.
Want to know more about the intricacies of data ingestion? Speak to our experts by filling out this form.
Indeed, data automation can bring to the fore the true potential of humans, machines, and data.
Yet, studies like the one mentioned above, and others have shown that the pace of automatic data extraction and ingestion has not picked up to the degree one would have liked it to be.
Surprising, since one would believe that businesses do tend to lean towards such “digital robotization” to get ahead in the game. Also, to use data scientists or analysts for simply executing repetitive work which can, otherwise, be automated, is a waste of resources.
Quick Primer on Data Ingestion
Data extraction is crucial to the automation of structured data for use in the analysis. It provides data from multiple sources such as balance sheets, invoices, timesheets, contracts, and so on.
Data extraction is also the process of converting unstructured data into a more formal form since it is such structured data that yield meaningful insights for analytics. But the cycle does not stop at the mere mining of data.
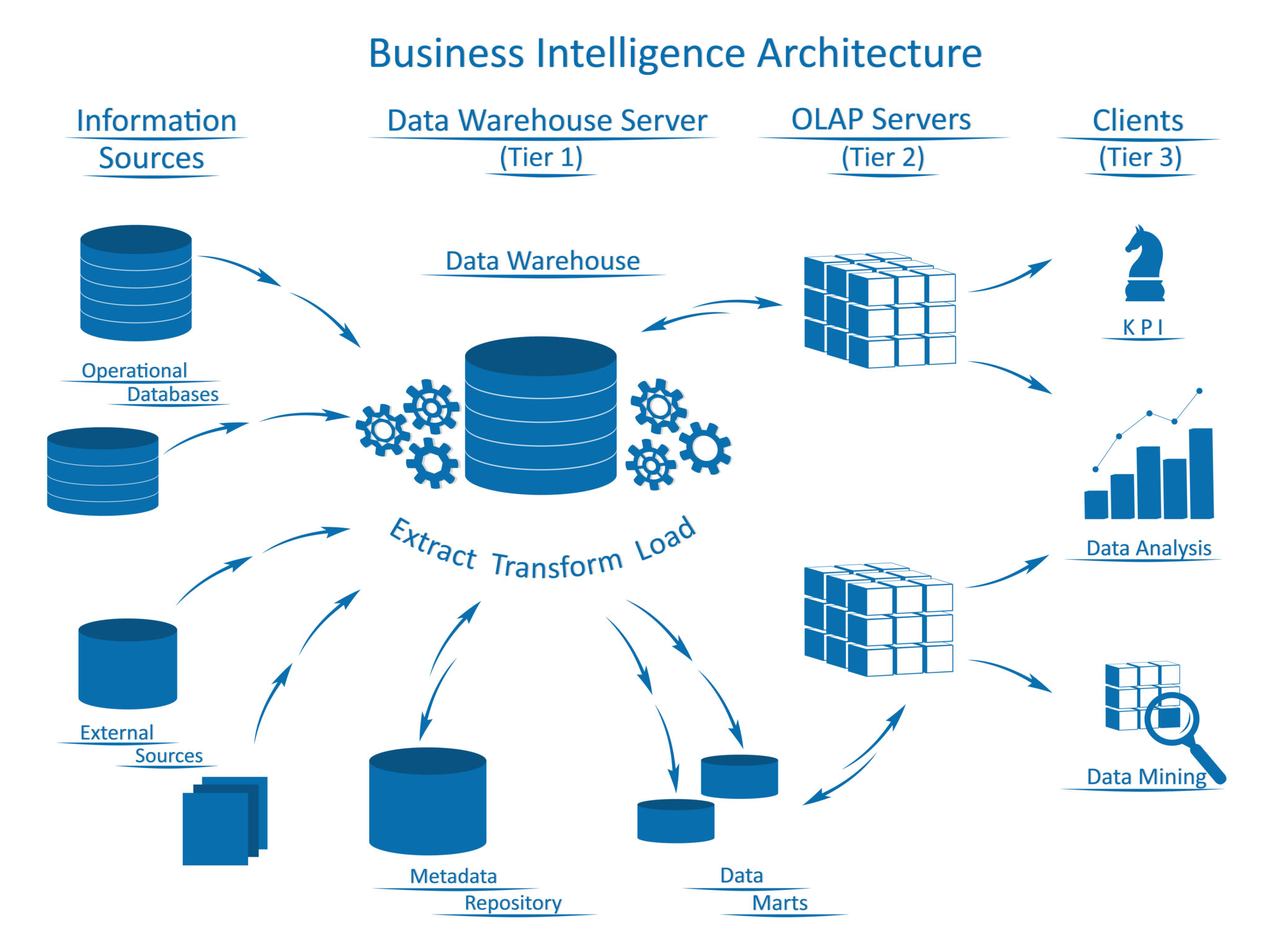
The data ingestion layer is the backbone of an analytics architecture.
How a data ingestion powers large data set usage in finance?
There are many types of data ingestion; extract, transform, load (ETL) are some of them. It has the following steps:
- Data extraction: Mining data from sources like databases or websites.
- Data transformation: In tune with specific business rules, that mined data is transformed. Includes data munging /cleaning, and then structuring it to match the schema of the target location such as a data lake or a data warehouse.
- Data loading: This ‘clean’ data is then loaded into the target location. There are many ways of ingesting data, often guided by the various models or architectures. Batch processing and real-time processing are the most commonly used.
- Batch processing: Here, at a pre-determined point in time, the ingestion layer collects and groups the source data. It then sends it to the intended destination. Triggers could be either the activation of certain conditions or just a time/day schedule. A lot of banks, for example, use batch processing for customer statements, credit card billings, and so on as it is not only convenient but cost-effective.
- Real-time processing: This is also called stream processing, and as the name suggests, data is sourced, transformed, and loaded in real-time; in fact as soon as it’s created. Obviously, this is more expensive compared to batch processing as it requires systems to monitor sources 24×7.
Why Automated Data Extraction and Data Ingestion
Compared to other sectors, Finance pegs a high priority on improved analyses, which, in turn, means data integration must happen at a higher frequency than in other sectors.
FinTech operations are about continuously imbibing a constant stream of information. Such ingestion has to live up to a high standard of quality control because an uncaught mistake can quickly turn into losses of millions of dollars.
Fundraising, reporting, and management systems are critical to the business of any FII and banking.
Here, the manual process of tracking investors and their investment choices results in time being wasted in low-value activities and thus is ideally placed for automation. The benefits of this are many, some of which we enumerate here:
- Quicker Decision Making: To reiterate, in comparison to ingesting data manually, automation allows users to even extract insights inside unstructured data.
- Highly scalable: Manual data ingestion is only as fast as the person inputting the data. Hence, scaling up will always be a problem. But with automation, FIs can start with a handful of data sources and automate them, and then scale up data automation over time.
- Cost savings: Think of what a company has to pay to manually key in say 1000+ invoices, and the low cost involved when the process is fully automated.
- Low risks: Data is the start-off point in any business, and the same is true for a finance company or operation. Any error in the data ingestion process means not only a monetary loss but also that of reputation. Automated data ingestion mitigates that risk by eliminating human error that could be otherwise introduced during the ETL process.
- Improve time-to-market goals: Because of poor data quality or slow data ingestion, companies often complain of being unable to complete their analyses on time, and thus not been able to achieve their eventual business goals. So, the failure to launch your service or product in the market on time, means your business losing its competitive edge. Automation gets rid of this pain point to a very large extent.
In Part 2 of this post, we will detail the benefits of automatic data ingestion.
Here’s How Express Analytics’ Oyster CDP Can Help
Source and automate your dataflow from any channel in the format of your choice. Helps apply data validation rules automatically. Uses open source solutions and a mix of cloud-based frameworks like Amazon Web Services and Microsoft Azure.
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform