
Why Machine Learning Data Catalogs (MLDCs) are becoming popular
In part one of this blog post we had discussed what data catalogs are, and why there is an increase in their use by enterprises over the last two years.
In this second and final part of that post, we look at how artificial intelligence (AI), specifically machine learning (ML), has led to the birth of a new type of data catalog called machine learning data catalogs or MLDCs.
What is a Machine Learning Data Catalog?
But before going there, a quick recap: data catalogs are meant to override manual data tagging of your data by using automatic labeling.
Catalogs are essential to telling you where your data is stored, thus reducing the time taken to identify data and making it accessible for analytics. It’s an inventory of your organization’s data assets.
The manual system of data cataloging is no longer viable in the data-intensive world we stay in today, where, with each passing day, thousands of petabytes of data are generated.
MLDCs take the science of data cataloging even further. They help with two things: (a) tracking data lineage and (b) analyzing how data is being consumed internally.
The first is very important for addressing data governance requirements, especially after the passage of online privacy protection laws such as the GDPR.
MLDCs are of vital help to those enterprises operating in the Internet of Things (IoT) world where the flow of streaming data is largely in real-time and analytics is often from the device edge.
In this kind of scenario, time is a critical factor, so MLDCs help agile organizations which do not have the time to go through standard profiling processes.
In addition, enterprises can use AI capabilities to uncover metadata from current and new data sets, then tag them as per the business rules to help locate and use documentation as and when needed.
Transform your business using Express Analytics’ machine learning solutions
In one of its reports on the early adoption of MLDCs commissioned by Waterline Data, Forrester has said that AI-run data catalogs were overcoming the most difficult challenges in this field.
What can Machine Learning Data Catalogs achieve? The Positives
Forrester’s survey showed that nearly half of MLDC adopters had attained, or hoped to achieve, benefits such as:
- Better control over data management and data governance;
- Improved understanding of data utilization and behavior for data security and support;
- A better understanding of the data to drive insights and actions;
- The ability to automate a significant number of developmental, administrative, and governance tasks.
Here’s Why Machine Learning Data Catalogs MLDCs are selling like hot potatoes
Market demand for MLDCs is growing because:
- there’s been an explosion in the volume and variety of data that can no longer be tagged using typical data catalogs
- of regulatory demands around data privacy
- of the availability of cheaper technology that’s leading to the democratization of data

We live in a digital economy today, which is forcing almost every enterprise to start managing its data.
The day is not far when enterprises will be data-centric. In this kind of scenario, standalone data catalogs that merely “store” metadata across systems will no longer be enough.
Companies are actively looking at the holistic management of data, and one of the steps in that is to tie up the metadata with the master data, reference data, interactions, and relationships data.
That’s where ML-powered modern data management platforms come in. Because of AI, they are a more comprehensive solution to meet an enterprise’s data cataloging demand; even throwing up “intelligent” suggestions to make data recall even more robust.
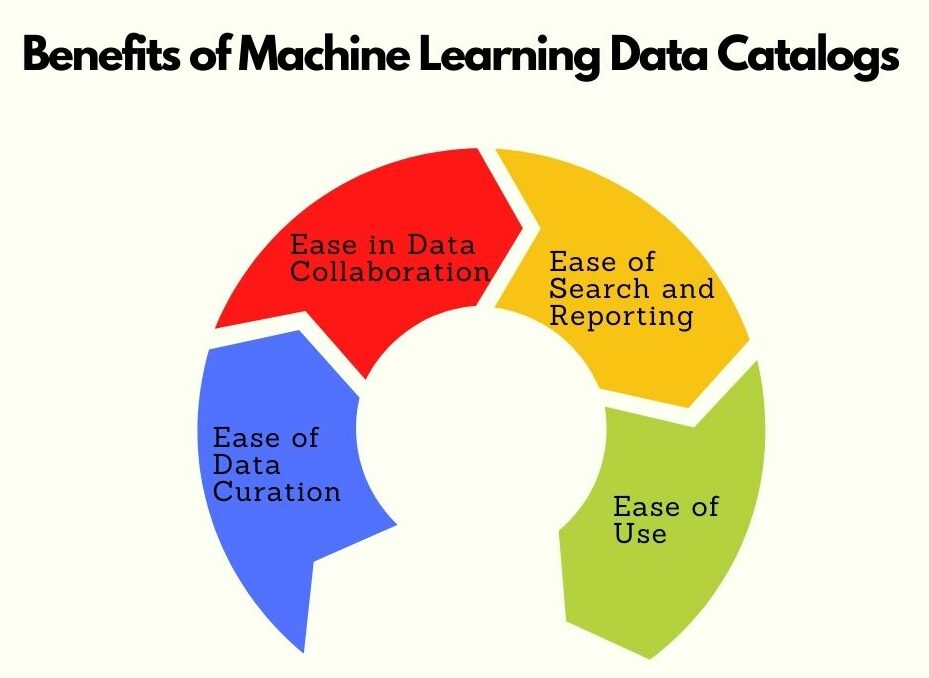
What Benefits do Machine Learning Data Catalogs offer?
Here are some of the benefits of MLDCs:
- Ease of use
- Ease of search and reporting
- Ease of data curation
- Ease in data collaboration
All of which lead to enterprise-wide consistency, eventually.
Who Benefits from Data Catalogs?
While Machine Learning Data Catalogs provide the best possible way of managing, monitoring, and improving the use of enterprise data assets, they can be of great benefit especially to those companies working in heavily regulated industries such as healthcare, finance, and defense.
In conclusion: AI-driven data catalogs provide a simple, search-based discovery to find relevant data along with a holistic view of the data to help users understand the data—where the data is coming from, how it’s being used, what other data it’s related to, the business context for that data, and the quality of the data.
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform