
What is Data Wrangling?
Detect and manage outliers in data wrangling efficiently. Talk to our experts for machine learning solutions
Importance of Data Wrangling in Data-Driven Marketing
Data wrangling has been the complete domain of trained and professional data scientists; this process may require up to 80% of the analysis cycle.
Data wrangling tools rapidly format siloed information from social media, transactional, and various origins to convert customer reactions into insights that are used to boost marketing efforts.
Boost customer loyalty
Customer information can be used by marketers to cultivate stronger connections with fresh and present customers.
By examining information from each interaction a client has had with a business, marketers can offer tailored client experiences according to real-time intelligence.
Data Wrangling Challenges
Inspecting use cases: Analysts should recognize use cases thoroughly by researching what subset of entities are suitable, whether they are attempting to forecast the likelihood of an event or evaluating a future amount.
Inspecting identical entities: After downloading impure data, it’s difficult to judge what’s unrelated and what’s related.
For instance, we consider “consumer” as an entity. The data sheet may have a consumer named “Simon Joseph.” Another column might contain a different consumer, “Simon J.”
In these situations, you have to deeply examine numerous factors while concluding the columns.
Exploring data: Eliminate redundancies in the data ahead of exploring the relationships between the results.
Preventing selection bias: Make sure that the training sample data describes the implementation sample.
One of the biggest challenges in machine learning today continues to be in automating data wrangling. One of the main hurdles here is data leakage.
The latter refers to the fact that during the training of the predictive model using ML, it uses data outside of the training large data set, which is unverified and unlabeled.
Data Wrangling vs. Data Cleaning vs. Data Mining
The activity of transforming and mapping data from one raw form to another is called data wrangling.
This involves feature engineering, aggregation and summarization of data, and data reformatting.
Data cleaning is the activity of taking impure data and storing it in precisely the same format, erasing, adjusting, or improving issues associated with data validity.
The data cleaning process can start only after reviewing and characterizing the data source.
Data mining is a narrower field that identifies invisible patterns in massive datasets for forecasting results in the future.
Important Characteristics of Data Wrangling
Useable data
It formats the information for the end user, which enhances data usability.
Data preparation
Data preparation is challenging to achieve better results from deep learning and ML initiatives, so data munging is important.
Automation
Data wrangling techniques like automated data integration tools clean and transform raw data into a standard form that can be used frequently according to end needs.
Businesses use this standardized data to adopt challenging cross-dataset analytics.
Saves time
As mentioned earlier, data analysts spend enough time sourcing data from numerous origins and updating data sets instead of conducting fundamental analysis.
Data blending offers errorless data to analysts quickly.
What are the Tools and Techniques of Data Wrangling?
It has been observed that about 80% of data analysts spend most of their time in data wrangling and not the actual analysis.
Data wranglers are often hired for the job if they have one or more of the following skillsets: Knowledge in a statistical language such as R or Python, knowledge in other programming languages such as SQL, PHP, Scala, etc.
They use certain tools and techniques for data wrangling, as illustrated below:
- Excel Spreadsheets: this is the most basic structuring tool for data munging
- OpenRefine: a more sophisticated computer program than Excel
- Tabula: often referred to as the “all-in-one” data wrangling solution
- CSVKit: for conversion of data
- Python: Numerical Python comes with many operational features. The Python library provides vectorization of mathematical operations on the NumPy array type, which speeds up performance and execution
- Pandas: this one is designed for fast and easy data analysis operations.
- Plotly: mostly used for interactive graphs like line and scatter plots, bar charts, heatmaps, etc
R tools
- Dplyr: a “must-have” data wrangling R framing tool
- Purrr: helpful in list function operations and checking for mistakes
- Splitstackshape: very useful for shaping complex data sets and simplifying visualization
- JSOnline: a useful parsing tool
Why the Need for Automated Solutions?
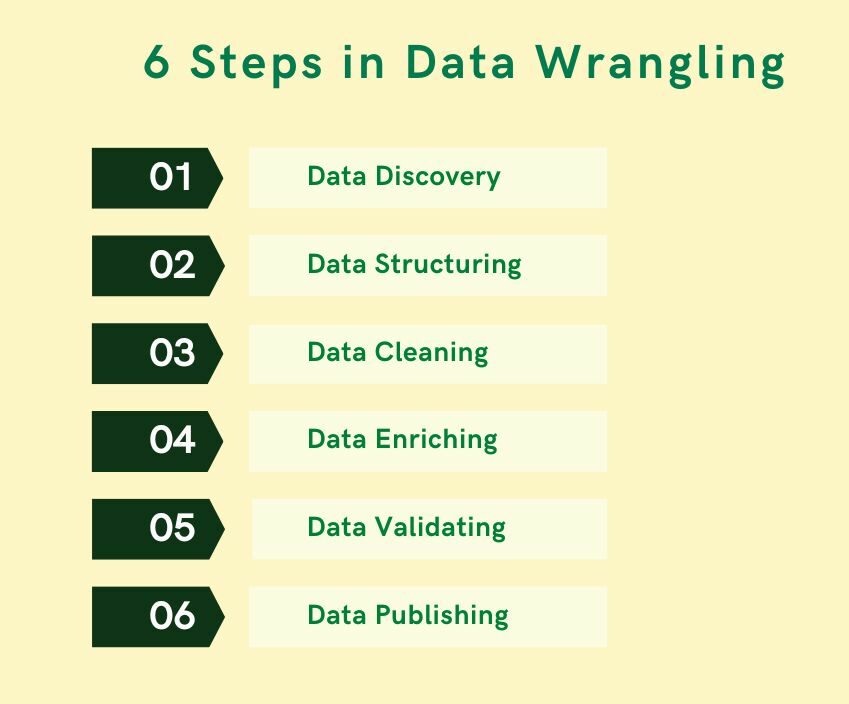
What are the 6 Steps in Data Wrangling?
It is often said that while data blending is the most important first step in data analysis, it is the most ignored because it is also the most tedious.
To prepare your data for analysis, as part of data wrangling, there are 6 basic steps one needs to follow.
They are:
Data Discovery: This is an all-encompassing term that describes understanding what your data is all about. In this first step of the data wrangling process, you get familiar with your data.
Data Structuring: When you collect raw data, it initially is in all shapes and sizes, and has no definite structure.
Such data needs to be restructured to suit the analytical model that your enterprise plans to deploy
Data Cleaning: Raw data comes with some errors that need to be fixed before data is passed on to the next stage.
Cleaning involves the tackling of outliers, making corrections, or deleting bad data completely
Data Enriching: By this stage, you have kind of become familiar with the data in hand.
Now is the time to ask yourself this question – do you need to embellish the raw data? Do you want to augment it with other data?
Data Validating: This activity surfaces data quality issues, and they have to be addressed with the necessary transformations.
The rules of validation rules require repetitive programming steps to check the authenticity and the quality of your data
Data Publishing: Once all the above steps are completed, the final output of your data wrangling efforts is pushed downstream for your analytics needs.
It is a core iterative process that throws up the cleanest, most useful data possible before you start your actual analysis.
When Should You Use Data Wrangling?
You need to use this process when you obtain data from multiple origins and require modification before adding it to a database and executing queries.
Listed below are a few examples of when data wrangling would be useful:
Gathering information from various countries:
Data from various origins like this has to be standardized to be queried together in a single big database.
Scraping data from websites: Data on websites is kept and displayed in a way that is readable and usable by humans.
When data is scraped from websites, it has to be organized into a format that is fit for querying and databases.
Additionally, it is also used to:
- Save steps related to the preparation and implementation of comparable datasets
- Find duplicates, anomalies, and outliers
- Preview and offer feedback
- Reshape and pivot data
- Aggregate data
- Merge information across different origins via joins
- Schedule a procedure to execute a trigger-oriented or time-oriented event
How Machine Learning can help in Data Wrangling
- Supervised ML: used for standardizing and consolidating individual data sources
- Classification: utilized to identify known patterns
- Normalization: used to restructure data into proper form.
- Unsupervised ML: used for exploration of unlabeled data
What are the Various Use Cases of Data Wrangling?
Some of the frequently seen use cases of data wrangling are highlighted below:
Financial insights
It can be used to identify insights invisible in data, forecast trends, and predict markets. It assists in making investment decisions.
Unified format
Various departments of the organization use multiple systems to collect data in numerous formats.
The process aids in the unification of data and converts it into a single format to offer a comprehensive view.
As it is, a majority of industries are still in the early stages of the adoption of AI for data analytics.
They face several hurdles: the cost, tackling data in silos, and the fact that it is not really easy for business analysts – those who do not have a data science or engineering background – to understand machine learning.
Poor data can prove to be a bitter pill. Are you looking to improve your enterprise data quality? Then, our customer data platform Oyster is just what the data doctor ordered. Its powerful AI-driven technology ensures a clean, trustworthy, and optimized customer database 24×7.
Click here to know more
The use of open source languages
11 Benefits of Data Wrangling
Data wrangling is an important part of organizing your data for analytics. This process has many advantages.
Here are some of the benefits:
Saves time: As we said earlier in this post, data analysts spend much of their time sourcing data from different channels and updating data sets rather than the actual analysis.
This process offers correct data to analysts within a certain timeframe.
Faster decision making: It helps managements take decisions faster within a short period of time.
The whole process comes with the objective of obtaining the best outputs in the shortest possible time.
Data wrangling assists in enhancing the decision making process by an organization’s management.
Helps data analysts and scientists: Data wrangling guarantees that clean data is handed over to the data analyst teams.
In turn, it helps the team to focus completely on the analysis part. They can also concentrate on data modeling and exploration processes.
Useable data: It improves data usability as it formats data for the end user.
Helps with data flows: It helps to rapidly build data flows inside a user interface and effortlessly schedule and mechanize the data flow course.
Aggregation: It helps integrate different types of data and their sources like database catalogs, web services, files, and so on.
Handling big data: It helps end users process extremely large volumes of data effortlessly.
Stops leakage: It is used to control the problem of data leakage while deploying machine learning and deep learning technologies.
Data preparation: The correct data preparation is essential in achieving good results from ML and deep learning projects, that’s why data munging is important.
Removes errors: By ensuring data is in a reliable state before it is analyzed and leveraged, data wrangling removes the risks associated with faulty or incomplete data.
Overall, data wrangling improves the data analytics process.
How Express Analytics can help with Your Data Wrangling Process
Our years of experience in handling data have shown that the data wrangling process is the most important first step in data analytics.
Our process includes all the six activities enumerated above like data discovery, etc, to prepare your enterprise data for analysis.
Our data wrangling process helps you find intelligence within your most disparate data sources.
We fix human error in the collection and labeling of data and also validate each data source.
All of this helps place actionable and accurate data in the hands of your data analysts, helping them to focus on their main task of data analysis.
Thus, our process helps your enterprise reduce the time spent collecting and organizing the data and, in the long term, helps your business seniors make better-informed decisions.
Click on the banner below to watch our three-part webinar – Don’t wrestle with your data: the what, why & how of data wrangling. In each of these webinars, our in-house analysts walk you through topics like, “How to craft a holistic data quality and management strategy” and “The trade-off between model accuracy and model processing speed”.
Click to watch our 3-part free webinar series on the Why, What & How Of Data Wrangling.
In conclusion: Given the amount of data being generated almost every minute today, if more ways of automating the data wrangling process are not found soon, there is a very high probability that much of the data the world produces shall continue to just sit idle, and not deliver any value to the enterprise at all.
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.