- What is an Analytics Platform and how is it different from a Transactional Platform?
- What prevents organizations from exploiting the existing data in their databases for Analytics?
- Who are the new entrants in the market with analytics platforms offerings?
- What is the long-term direction of the market?
- Can I afford an analytics platform?
- What is the correct measure of the cost of an analytic platform?
Let us ponder on the first question:
What is an Analytics Platform and how is it different from a transactional Platform?
A bit of Background
For the last 40 years or so the entire technology industry has been focused on solving just one problem.
- How to improve the ability to record and manage transactions?
This unrelenting focus has lead to enormous improvements in the ability to record transactions. We have become so good that today we are able to record transactions in micro and Nanoseconds. This has given rise to high-frequency trading on the stock markets, massive scale collaboration of billions of people on social media, and recording sensor data from machines. It is well understood that the core requirement of a transaction management system is to be able to
- Create a new record
- Read a single record
- Update any field of that record
- Delete a record
- Save the record.
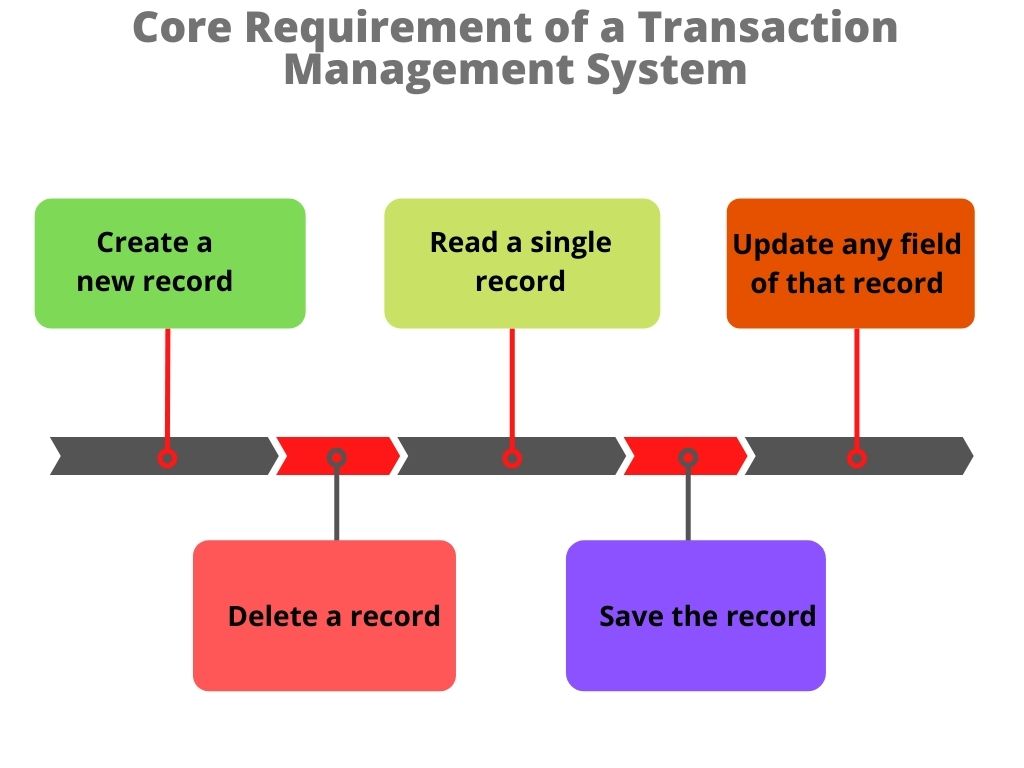
These few functions (CRUDS) all operate on a single record. Hence we have developed database systems that are highly efficient in selecting a needle from the proverbial haystack. To achieve this singular objective we record the complete record as a row. Each row can have fields that are number, date, or text type. In the late 90s and 2000’s, we have struggled to modify these database systems to accommodate audio and video content without much success. So every time we need to read a few fields in a record, we need to bring the entire record in the memory before we can operate on it.
So if the record has 100 fields and I mostly query the 10 most frequently used fields, I am moving the whole record even though I have no use for the 90% of the fields in my current operation. When I have to read in millions of records in the memory this becomes a wasteful use of precious resources such as server memory, CPU at an enormous cost of I/O from disk. The result is a system that is sluggish and doesn’t respond before the train of thought has left the station.
What about Now?
In the last decade, we have found that the amount of data we have stored in our databases has grown humongous in size and we are unable to access that data efficiently. This lead to looking at different approaches to storing and accessing the data. First, we analyzed the queries we frequently ran and discovered that only 5-10% of the fields of a record are used in our queries. This lead to a different way to store data in databases. This approach stores data as columns rather than a complete record.
This approach is called the columnar database system. Since each column of a table has a single data type we can use compression techniques to reduce the size of the database. This in turn reduces the I/O necessary to retrieve a large volume of data and improves query performance dramatically. Second, we discovered that the clock speed of the CPU and the memory has hit a wall, so we adopted a parallel processing approach using multicore CPUs. Taking this one step further we created massively parallel clusters of commodity servers that work together to crunch a very large amount of data very effectively.
During the last decade, we have also uncoupled the hardware and software in servers. Today we are able to define what a cluster delivers by the software installed on it. Completely software-defined servers give us the ability to use commodity hardware and open-source software to create Big Data crunching abilities that are easy to configure and change. They bring fluidity to our operations. We have been moving from brittle to flexible architectures.
Good but not good enough!
So currently we are able to record and retrieve large volumes (Gigabytes, terabytes, and Petabytes) efficiently. But, how do we make sense of the large volumes of data effectively? We are attempting to develop machine-learning techniques to be able to analyze data at high volume because it is not humanly possible to read, understand and analyze large amounts of granular data. Along with this increased velocity of data generation, the data is also becoming more unstructured, sparse, and coming at us from all channels. Even channels that are digital and modern are starting to get left behind. Today texting is preferred over email and written letters are not even used to fire employees or divorce notices. World over, we frequently use three or four-letter acronyms from slang. So LOL, PFA, and GTG are used routinely in communication. Our interactions have become informal, sparse, multi-channel, and asynchronous. Yet our desire to be understood has never been greater.
We expect our service providers to divine our expectations and be ready to serve us without so much as expressing our needs. We are migrating to an era when an organization needs to:
- observe us,
- understand our desires,
- appreciate our tastes,
- analyze our past behavior
- serve us graciously
- In real-time
or we are ready to change our service providers in a flash.
What should an analytics platform provide?
All this has led to the desire for an Analytics platform that will allow us to analyze the data and extract meaning and nuances from it. The modern analytic platform needs to do the following functions efficiently:
- Select a few columns from a very large number of records
- Select sets of records based on different criteria
- Create new sets from the intersection or union of these record sets
- Create derived fields from the few columns selected to enrich this data
- Create algorithms to recognize the trends in this data
- The project discovered trends in future
- Describe the patterns recognized
- Classify similar data together
- Predict the likelihood of events
- Prescribe corrective action
- Infer meaning from seemingly dissimilar data
- Present data in an easy to understand the visual image
The modern analytic platform has many more requirements that are contradictory to transactional platforms. In the following posts, we will discuss the answers to the remaining questions. The list above is an incomplete one. I am sure you have a lot more functions that you feel are important. Let me know and I will keep adding it to the list.
In the next blog, I will discuss the reasons why organizations are unable to exploit existing data in the company. Stay tuned.