What is a Recommendation Engine and How it Works?
In today’s digital world, a recommendation engine is one of the most powerful tools for marketing.
What is A Recommendation Engine?
A recommendation engine is nothing but an information filtering system composed of machine learning algorithms that predict a given customer’s ratings or preferences for an item. A recommendation engine helps to address the challenge of information overload in the e-commerce space.
Thus, it can help in saving a lot of browsing time for customers, as it directs the user to products of he is most likely to like. Its personalization features improve customer engagement and retention.
Table of Contents
The idea of recommendation engines is also something you are already familiar with; Whether it is product recommendations on Amazon, movie recommendations on Netflix, or music suggestions on YouTube, recommender systems are already supporting many aspects of your experience online.
Foundation of Recommendation Engine
Consumer interaction data is the foundation for developing a recommendation system. More the consumer data more efficient the recommendation engine. The data consists of customers’ past behavior, customer relations with other users, and similarity between various items.
Amazon uses it to suggest products to customers based on their earlier purchases, most popular products, and also similar products. Finding patterns in consumer behavior data is the principle on which a recommender system operates.
Data collection is a crucial step in the development of a online recommendation engine. Data can be collected implicitly or explicitly.
Implicit data refers to information gathered from events like web search history, clicks, and order history. Explicit data is gathered from customer inputs – ratings and likes/dislikes.
Customer attributes like demographics (eg: age, gender) and psychographics (eg: interests, dislikes, etc) can facilitate identifying similar customers. Product features (eg: movie genre, actors, etc) can help in computing the similarity between products.
Increase Your ROI with Intelligent Product Recommendations
3 Types of Recommendation Engines
Broadly based on their operations recommender systems can be divided into 3 types:
1. Collaborative filtering: Focuses on analyzing customer behavior, activities, or preferences to predict ratings or suggest products. Collects large amounts of information on customers’ behavior, activities, or preferences to predict what users will like based on their similarities with other users.
Customer attributes like demographics and psychographics are used in identifying similar customers.
Amazon is the pioneer in implementing collaborative filtering; it works on collecting preferences from distinct users from which a customer * product matrix is developed. As we see in the following figure user (3) and user(m-1) have similar likes, so we can recommend item(n) to the user(3).
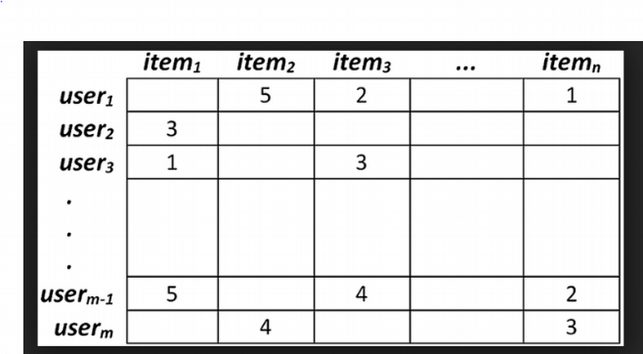
Collaborative filtering is further divided into user-item and item-item. User-item filtering looks for like-minded customers based on their common rating patterns. In item-item filtering similarity between pairs of items is calculated.
To summarize, collaborative filtering works on the principle: you are likely to like what others similar to you like ….. . Techniques like matrix factorization are used in collaborative filtering.

2. Content-Based System: The core idea of content-based filtering is: “if you like an item you will also like a ‘similar’ item…. ”. The algorithm recommends products that are similar to past transactions. The similarity of the items or the neighborhood is computed with techniques like cosine and euclidean distances.
An item-feature matrix is created by computing the TF-IDF values from product descriptions.
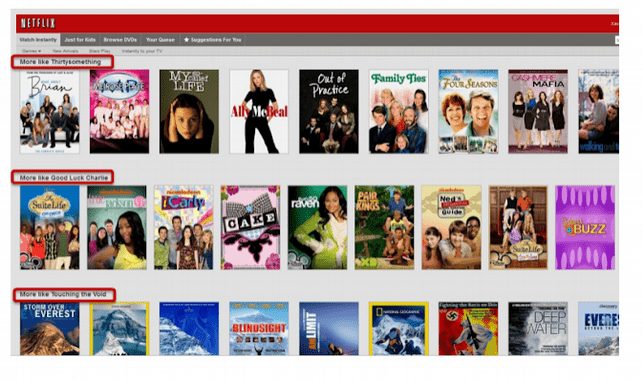
Major differences between content-based and collaborative filtering

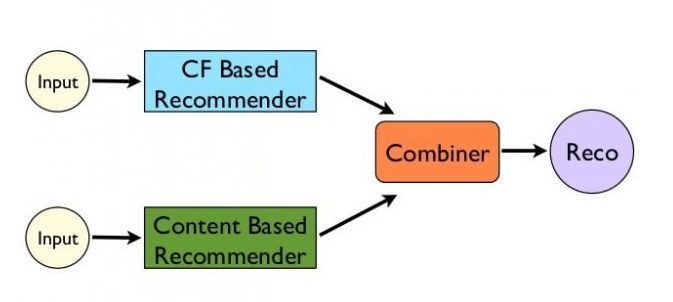
3. Hybrid model approach: Leverage both item metadata and transaction data to give recommendations. It combines the content-based and collaborative-based models. After evaluating the performance of pure recommendation engines (content & collaborative based) and hybrid models, it is observed that the hybrid model outperforms.
Netflix is a good example of the hybrid model implementation of a recommendation engine. It takes into account the features of movies along with the interest of users.
Here, using natural language processing (NLP), tags can be generated for the movie based on its story, and then tfidf scores can be used to calculate the similarity between the products and collaborative filtering can be used to recommend movies to the user depending on their features.
Challenges of Developing a Recommendation Engine
Due to the recommender system, insufficient data suffers from both the cold-start and sparsity problem. Cold start in general refers to the difficulty to instantiate the recommender system. Product cold start and user cold start are two distinct cold start issues.
Product cold start occurs when a new product is launched it lacks valuable user interactions, thus the engine fails to target the right group of customers.
Data alone does not drive your business. Decisions do. Speak to Our Experts to get a lowdown on how a recommender system can help your business.
The recommendation engine cold start issue can be addressed through content-based filtering- the metadata of the new product can be used to compute its similarity with already existing products.
User cold start challenge arises when a customer visits the engine for the very first time. The recommender fails to direct the customer to the best possible options since there is no past behavior monitored to understand his likes/dislikes or preferences.
Suggesting the most popular products aligning to the search can lead to some customer activity. Data sparsity arises when users, in general, interact with a limited number of products from the available potential products. Clustering similar users and products together can be one of the feasible solutions to address sparsity.
Implementation:
Open-source libraries like scikit-surprise and light FM can be used to develop your own recommendation engine.
References
LightFM’s documentation!
Recommender System
Machine Learning for Recommender systems — Part 1 (algorithms, evaluation and cold start)
Quick Guide to Build a Recommendation Engine in Python & R
An Engine that offers sophisticated Recommender algorithms
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform
No comments yet.