
Building A Recommender System In Machine Learning – A Primer : Part 2
In Part One of this post, you read about what is a recommender system in Machine Learning, the different classes, and the steps involved in building a recommendation engine.
In this second and last post, we shall now talk about how to build a recommendation engine using Neo4j a graph database management system.
What is Neo4j?
Essentially, Neo4j is a graph database management system that also provides the necessary tools to visualize and draw out important insights from the graph database.
The biggest advantage of using a graph data model is that one does not have to connect the entities within the data using special properties such as foreign keys. In graph databases, it becomes very easy to understand the relations between the entities as the structure of the stored data is not so much structured, yet it is well organized and very perceptible.
Imagine having a system on your computer that can create a database that is a replica of the business model that you drew on your management whiteboard? With Neo4j we can connect all the entities in a business with the help of the graph database model.
This allows us to not only focus on the entities but also on the way these entities interact with each other, thus giving a better idea of the bigger picture.
The world that we live in today is a connected ecosystem, be it the business that you might be running, or even your Facebook account for that matter. All the entities that exist around us are connected in some way or the other through different relationships.
Unlike other database management systems, graph databases represent the data in the form of nodes and edges. The nodes represent different entities in the data and the edges represent the relationships between them.
This helps us to maintain and visualize the data in the most natural and normal version unless you are like someone like Neo from the movie Matrix.
Let me give you an example.
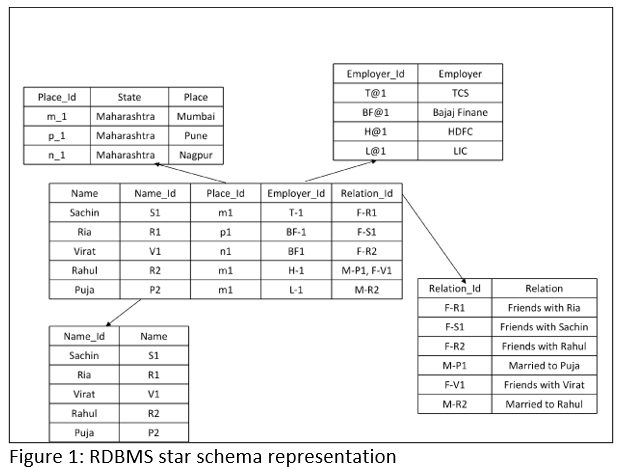
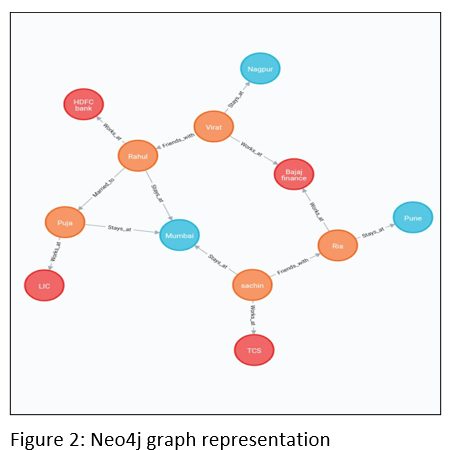
Take a look at figure 1 and figure 2:
Basically, these two charts represent a hypothetical example with the following pieces of information:
Just by reading the text, one can easily make out that the entities are connected through some relationships. Now, let us consider the above two diagrams individually. To store the complete information from the text into relational tables we had to create a star schema representation.
However, there are some problems with this approach. First, it becomes difficult to populate all the tables with the given information, and if someone wishes to update any new information then that information needs to be updated on its respective dimension table as well.
Whereas if you consider carrying out similar tasks in Neo4j then all you will need to do is write or create a statement in cipher for a respective node or a relationship. As far as updating any information on any node/relationship is concerned all one needs to do is write that information on that particular node/relationship only.
Start delivering customized experiences with AI-driven recommendation engines. Get in touch with our experts today!
Moreover, as the amount of complexity in the data increases the amount of effort one needs to put into carrying out CRUD (Create, Read, Update, Delete) queries on the data also increases. For example, if we wish to write a query just to find out which people in the data are colleagues then in SQL the query would be:
select employer.employer, employee.name
from the employee, employer
where employee.employer_id=employer.
And in cypher the same could be achieved by writing:
match (p1:Person)==[:Works_at]==>(c1: company)<==[:Works_at]==(p2: Person)
Return p1, p2, c1.
Neo4j vs MongoDB vs MySQL:
Since Neo4j is a NoSQL database, let’s discuss how it is different from some of its contemporaries in terms of its basic architecture and applications.
| Neo4j DB | Mongo DB | MySQL DB | |
| 1) | Neo4j is a graph database consisting of multiple units in the form of nodes. Information on nodes can be stored as both document and key-value pairs. | MongoDB is a document database consisting of multiple units where information about each unit is stored as a document. | MySQL is a relational database consisting of tables where information about each unit is stored in a row of tables. |
| 2) | The basic architecture of the database lets users explore the interactions between different nodes in the form of relationships. This enables one to draw important inferences from the data by using different algorithms like similarity-based, community detection-based algorithms, etc. | The basic architecture of the database allows the user to store the data in humongous volumes but does not provide any means for the user to visualize the data in form of a 3D connected ecosystem. | The architecture of MySQL allows the storage of data in the form of rows in tables based on primary and foreign keys. Based on relationships between tables, we can draw relevant inferences. |
| 3) | With the help of indexing, data extraction in Neo4j is faster compared to MySQL. | MongoDB is faster compared to MySQL while dealing with a large amount of data. | MySQL takes more time compared to Neo4j and MongoDB for large databases to extract data having relationships between tables. |
| 4) | Neo4j can be used for the following things:
Building Fraud detection systems. Building recommendation engines. Social network analysis. Graph visualization. Building a knowledge graph. |
MongoDB can be used for the following things:
Building single view applications. Creating catalogs Building IoT applications. Building content management systems. |
MySQL can be used for the following things:
Managing Customer data and transactions. Used in applications having heavily trafficked sites. |
Now that we know how graph database stores data concerning other NoSQL databases, let us see the specific case of Neo4j in the context of CAP (Consistency, Availability, Partition, Tolerance) trade-off in comparison to other NoSQL databases.
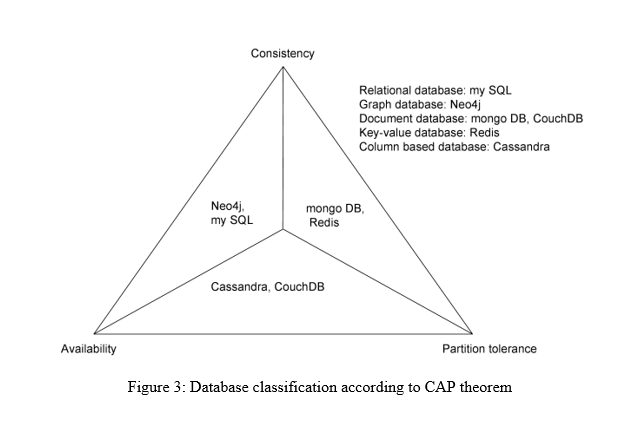
As we can see from the above figure, Neo4j is not partitioning tolerant. Moreover, it also does not support data distribution.
Unlike most of the aggregate data stores like column family, key-value, and document stores which have BASE consistency, Neo4j has ACID consistency, thus ensuring that the database is absolutely consistent and only atomic and isolated transactions are carried out.
Also, the results of these transactions stay unchanged even after the server fails or restarts.
For Neo4j to stay highly ACID-compliant, it follows master-slave architecture for data replication, in which a single node in a cluster is allowed to carry out all the write transactions. Due to this Neo4j falls short when it comes to carrying out multiple numbers of write operations simultaneously.
Here’s a real-life experience on the same: at my workplace, my team and I wanted to scan a relationship if each customer had at least one common event with other 38000 customers.
Fortunately, there were only about 0.25 million relationships to be written for every 1000 customers, extending this logic to the whole database we had to write new 10 million relationships in the database.
But since Neo4j does not use any kind of data partitioning and on top of that, it also uses master-slave architecture, carrying out this task became insanely difficult with Neo4j.
Here is one more instance: Neo4j takes O(1) amount of time whenever it needs to search for some specific information. But sometimes we need to perform more than just some search operations on our database.
The other day my team and I had to churn out a handful of recommendations for customers because of their recent purchases. On my company’s database, there are a total of 38000 customers and 87000 products and the total number of interactions between the customers and the product is approximately 1.7 million.
When we tried to generate recommendations for each customer with a collaborative filtering method followed by the Jaccard similarity algorithm, we had to wait approximately 6 hours to get the results.
What I have experienced is that whenever the Neo4j has to carry out any computationally challenging task on a large dataset it usually takes a considerable amount of time.
Data alone does not drive your business. Decisions do. Speak to Our Experts to get a lowdown on how a recommender system can help your business.
Setting Up Neo4j
Now that we’ve figured out what is Neo4j, its pros and cons, let’s get down to building one for a (hypothetical) e-commerce firm (insert here the link of Part 1). But before building such a recommender system, you need to download the desktop version of the Neo4j.
As a beginner, one should start with “Neo4j-Desktop Explore”. It has all the built-in libraries and all the development tools like the Neo4j ETL tool available in the Community Edition.
The installation process is simple and is well explained over Installation
After Installation one can start using the Neo4j browser for querying and get familiar with the user interface
Neo4j Browser User Interface Guide
After a certain amount of knowledge on Neo4j Desktop one can start working with:
Neo4j Causal Clustering
It is well suited for production environments because “Neo4j Causal Clustering” provides three main features:
Safety: Core servers provide a fault-tolerant platform for transaction processing which will remain available while a simple majority of those Core Servers are functioning.
Scale: “Read Replicas” provide a massively scalable platform for graph queries that enables very large graph workloads to be executed in a widely distributed topology.
Causal Consistency: When invoked, a client application is guaranteed to read at least its own writes.
(Note: In a multiple node cluster setup, only one node is assigned with the “Leader” role while all other nodes are assigned with the “Follower” role.)
In the Leader node we can perform all the operations (eg: writing, reading) while in follower, a copy of the leader node is formed where we can only perform the read /searching operations.
Setting Up Configurations In Neo4j
Heap Size: The Java heap is the amount of memory allocated to applications running in the JVM so the higher the memory allocated better the operation as a beginner one can set the heap size around 1-4GB but if we talk about the production environment then one should go For higher RAM and set up the size to optimize the RAM’s availability.
While working on any of the above types of setup one may find out about the high time consumption on Neo4j while querying, so the basic step is to set up the initial and maximum heap size.
(Note: Make sure heap size is smaller than the RAM available on the System as if you attempt to assign all RAM to the Neo4j Java process through heap allocation, you leave 0 RAM available for any other process which may cause a memory error.)
Page Cache Size: This is used to cache the Neo4j data as stored on a disk. Ensuring that most of the graph data from disk are cached in memory will help avoid costly disk access.
Setting Up Drivers For Neo4J
We can use a specified language if we want to automize or if we want to run the query in batches or storing multiple data tables returned from multiple queries into one based on the use cases
Neo4j supports a binary protocol called “Bolt”. It is based on the PackStream serialization and supports the cipher type system, protocol versioning, authentication, and TLS via certificates. For Neo4j Clusters, Bolt provides smart client routing with load balancing and failover.
The binary protocol is enabled in Neo4j by default, so you can use any language driver that supports it.
Neo4j officially provides drivers for .Net, Java, JavaScript, Go, and Python.
You can find detailed information about the official drivers in the Neo4j Driver Manual.
For more details on the protocol implementation, see the implementer’s documentation.
(Note: There are some community drivers available for other languages too, but these are not officially supported, so if possible, one should try for official drivers.)
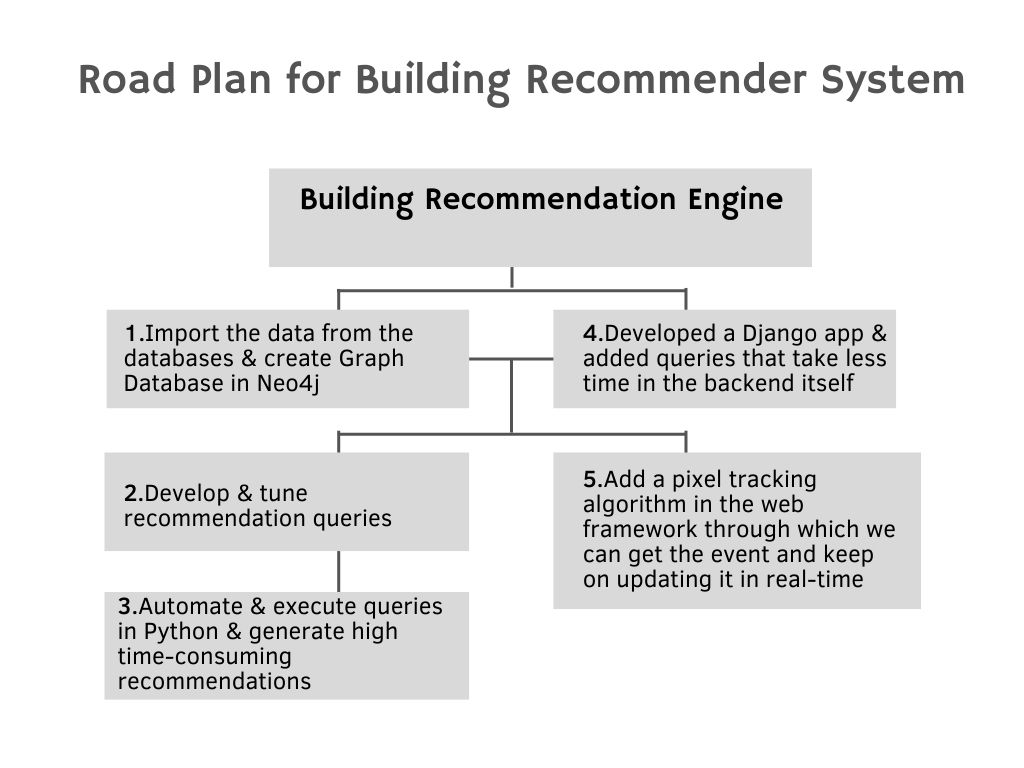
Road Plan/How We Did It
- Import the data from the databases and create Graph Database in Neo4j
- Develop and tune recommendation queries
- Automate and execute those queries in Python and generate high time-consuming recommendations like collaborative filtering algorithms in a span of a day using multi-threading to use all the nodes
- Developed a Django app and added queries that take less time in the backend itself.
- Add a pixel tracking algorithm in the web framework through which we can get the event and keep on updating it in real-time
Now, in our case of building a recommender system with the Neo4j, we loaded the data from the database in the CSV format using the ETL tool and then created the nodes, relationships, and properties.
Our team then started working on recommendation algorithms and wrote the cipher queries for all kinds of algorithms.
We learned that a query that has more filter or mathematical operation tends to consume more time, so we just tried to use all the available nodes while optimizing the RAM of each node by setting up heap size by connecting it with Python and returned a list of CSV for all kind of recommendations.
Please do recall from the first part of this blog post that Neo4j’s basic structure is built on “Nodes”, “Relationship”, and “Properties”.
A quick recap: A Node is a data or record in a graph database and a Relationship is an element using which we connect two nodes of a graph. This relationship creates a pattern that associates two chunks of information together and defines a flow by assigning a direction to it.
We can add pieces of information to our nodes and relationships by assigning properties to them.
Now that we are all set, you may recall we had spoken of at least 3 ways we can use this Neo4j based recommendation engine for customers of our e-commerce firm in Part One of this post:
- Recommendation based on a customer’s recent history
- Recommendation based on a product similar to the product a customer was surfing for in real-time
- User-user collaborative filtering based recommendation
Each of the above has been extensively explained in part one of this blog post in theory so all you now have to do is to use your newly built recommender system using the Neo4j platform to throw up recommendations for the shoppers using the fictitious e-commerce firm.
Use Cases of Recommendation Engine
To get a better idea of the Neo4j’s versatility in terms of graph database applications let us look at its use cases:
Movie Recommendation Engine:
Neo4j was used by Express Analytics in making a movie recommendation engine. We used Neo4j to store and loaded the movie details instead from a CSV file. The structure of the database is given below in Figure 4. The schema consists of nodes for movie, production company, production country, language, actor, director, genre, collection name, and user. Each node has its own properties to store data.
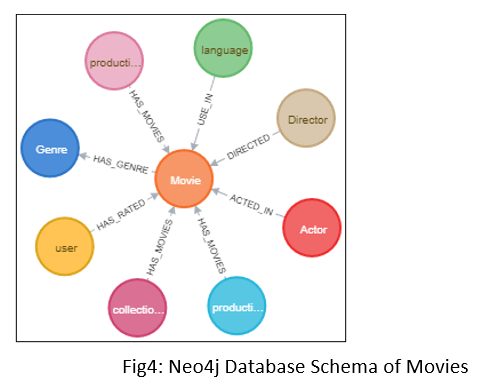
Due to the fast retrieval speed of Neo4j, the EA team used it to extract the data and then used that data to train the machine learning model to speed up the extraction process.
After generating the recommendations, our team stored them in the respective movie nodes. So, while showing the recommendation on the website, it used Noe4j for faster extraction and showed the respective recommendation for the given movie.
Thus, Neo4j makes it easy to make an item to item collaborative model. Due to graphical schema and using cipher queries on user nodes of given schema, it is easy to find recommendations based on the users who watched the given movie, also watched the recommended movies.
This model was injected into the movie recommendation website (client-side). It covered all the movies from all over the world with recommendations that cater to the taste of the user.
Telecommunication:
In the telecommunication field, Neo4j, by its own account, is used by leading telecommunication companies, including Telenor.
On its online self-service management portal, Telenor manages subscriptions and user access to its business mobile subscription.
But due to a large number of users and users’ expectation of real-time response from Telenor’s online system, they found that their SQL queries were not performing well enough and were not up to the mark. To tackle this, the company used Neo4j to serve the large database.
In the end, Telenor set its database for both corporate and residential customers due to the high speed of Neo4j and ease of to access the data and its maintenance.
Governance:
Due to the huge amount of data, any government body needs the tool to find data connections between different databases across different departments which helps in solving problems like preventing crime, improving fiscal responsibility, and providing transparency in its workings.
For example, the US Army has used Neo4j for maintaining its equipment database due to the massive amount of equipment it has. Earlier they were using a mainframe-based system to manage the data, but due to increasing and changing data, it was becoming difficult to maintain the data.
Using nodes, properties, and relationships of a graph database, data was stored in Neo4j. With this database, they were able to extract which equipment needs maintenance on a priority basis by querying the database.
References:
When Connected Data Matters Most
System Properties Comparison MongoDB vs. Neo4j vs. Redis
How many nodes are required to set up a distributed system in order to test CAP theorem?
Post Written By: Shubham Patidar, Devendra Lohar, Niraj Harwate, Pankaj Katkar and Vinay Dabhade.
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform