What is Dimensional Modeling
Profile Dimension (aka Junk Dimension aka Mystery Dimension)
Hello readers! I hope you all are enjoying the colorful spring! This time I am going to tell you a story about a new friend of mine, who lives on the Main Street of the Dimensional Modeling town and goes by a whole bunch of different names! Know more about what is dimensional modeling in data warehouse?
Dimensional Data Modeling is a data structure technique utilized for storing data in a data warehouse design to advance the data retrieval.
I am not sure how & from where he got all these names, but, It Is What It Is … As Data Warehouse Architects, we usually know the two kinds, namely, Dimensions & Facts, very basic, right? But then, every once in a while, we have our “encounters of the third kind”… the attributes that are neither dimensions nor facts! This new friend of mine helps us deal with these!
Scenario: Last month, we kicked off a new project to build a new DataMart for the supply chain group here. Everybody’s calendar got filled with a lot of meetings, meetings to discuss the project requirements, meetings to chalk out the estimates & the plan. Life was cool & I was doing my most favorite stuff, data modeling for the new project. I came up with a beautiful design, right out of the pages of a Ralph Kimball book with 5 dimensions, and 7 measures, and I was on my way to the star schema heaven. Suddenly I stumbled upon the user’s awkward questions: – Where is such and such flag? Where’s the blah-blah type? Why can’t I see that XYZ code? Did I wonder if we really need all of those junk attributes for BI? Well, it turned out that those standalone codes & flags & types really meant a lot for the business.
Know the Importance of Dimensional Model in Creating Data Warehouse?
Traditional Approaches & the issues: I had 2 options in my mind at that time to deal with this situation:
- Create new tiny dimensions for all of these attributes. But then, I was worried that my good-looking, picture-perfect model is going to get crowded with all these new dimensions that have nothing much to them other than just those codes, flags & types.
- Add all these transactional attributes to my fact table. But then, my fact table won’t just stand for 100 million rows of these sparsely populated attributes.
I didn’t like either of the options. And then, like Captain America, this new friend of mine, the “PROFILE” Dimension, came in to save the world, or at least my model!
Concept: A profile dimension is a dimension that holds all the unique or valid combinations of a set of columns, and assigns a unique key to each combination. This key is then hooked up onto the fact table. The set of columns that this dimension encompasses are usually low cardinality attributes like flags, types, codes & statutes, etc. These attributes do not necessarily have a direct correlation or relationship with each other but are only housed in a single dimension table.
Example of Dimensional Modeling
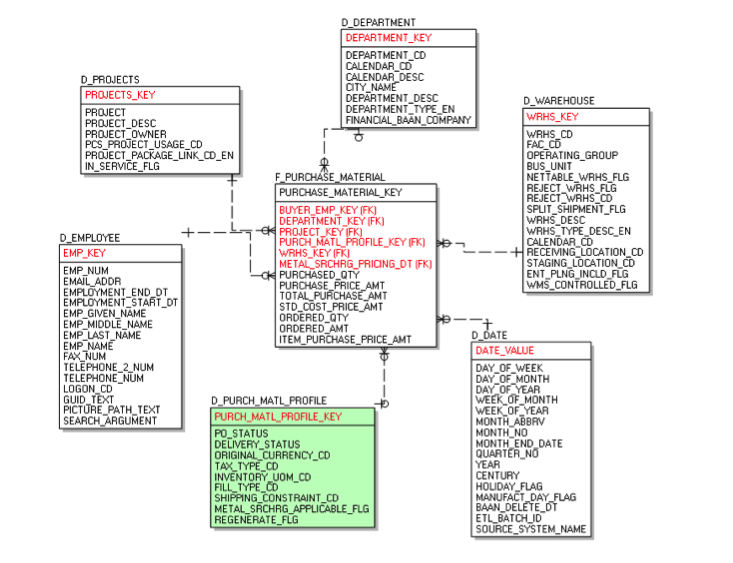
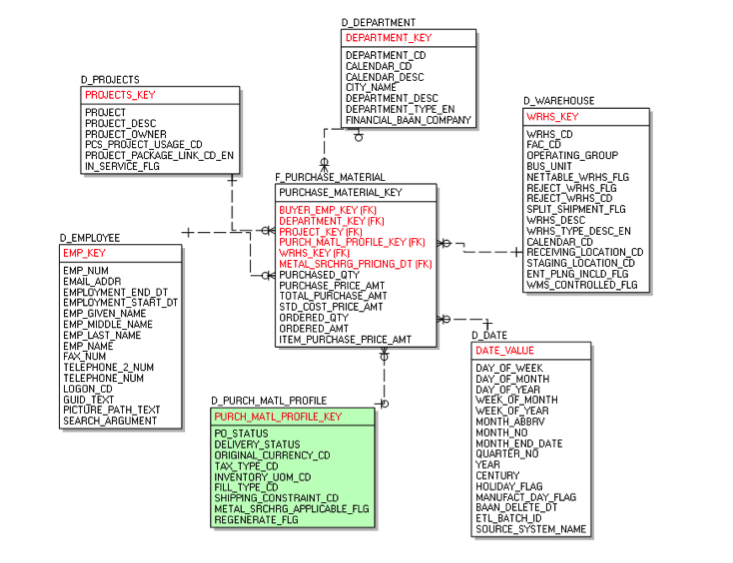
Let me tell you more about the exact situation I was trying to resolve. We had a Purchasing transactional table from the ERP system that needed to be fed into the DataMart. Apart from the 5 dimensions & 5 measures that I talked about earlier, this transactional table had several codes, statuses & flags.
All these standalone codes, statuses & flags were moved to a profile dimension (dimensional modeling in data warehouse). Here is how it looks in the model. Please take a look at the profile dimension (dimensional modeling in data warehouse) which is marked in GREEN. Of course, this is a much-simplified version of the actual star schema, just to explain the concept.
Advantages Of Dimensional Modeling
A profile dimension (dimensional modeling in data warehouse) allows all the columns to be queriable, while only adding one column to the fact table, and providing a much more efficient solution in comparison to either creating multiple dimensions, or leaving all the data in the fact table.
By moving such transactional attributes to a profile dimension, you’ve got fewer indexes on the fact table which might be important depending on the size.
Data Population: A key consideration when populating the profile dimension is, how many combinations are technically possible v/s how many actually exist in the data set. If the number of all possible combinations is too high, the profile dimension size may be unmanageable.
Also, many of the technically possible combinations may not even make sense in reality. In such cases, populating only the combinations that exist in the data set makes the design more efficient.
On the other hand, you are safe to create all possible combinations, if the attributes have a fixed set of values, like Boolean, or codes from a known finite set, because you can be sure you’ve created a dimension row for every combination that the data set might have.
If there are free-form string columns, then you need to make sure your ETL can generate new dimension rows and surrogate keys as new combinations are created in the source system.
As I mentioned earlier, this dimension is also called a ”Junk Dimension” or a “Mystery Dimension”, because it houses all those junk/mystery transactional fields that are neither dimensions nor facts. I hope you would find this new dimension table concept helpful in taking care of the outlier attributes in your data model… Happy Modeling!
An Engine That Drives Customer Intelligence
Oyster is not just a customer data platform (CDP). It is the world’s first customer insights platform (CIP). Why? At its core is your customer. Oyster is a “data unifying software.”
Liked This Article?
Gain more insights, case studies, information on our product, customer data platform